
Emotion-to-Audio Spec
The 6 constraints I write before designing


Most producers don’t buy audio early for “better sound.”
👉 They buy it to reduce risk.
Because when emotion lives as adjectives, the project ships late surprises:
“Make it warmer.”
“Make it more premium.”
“Make it emotional.”
👆 Those are not specifications. 👆
They create expensive wrong turns.
So I start with a mechanism: EmotiTone.
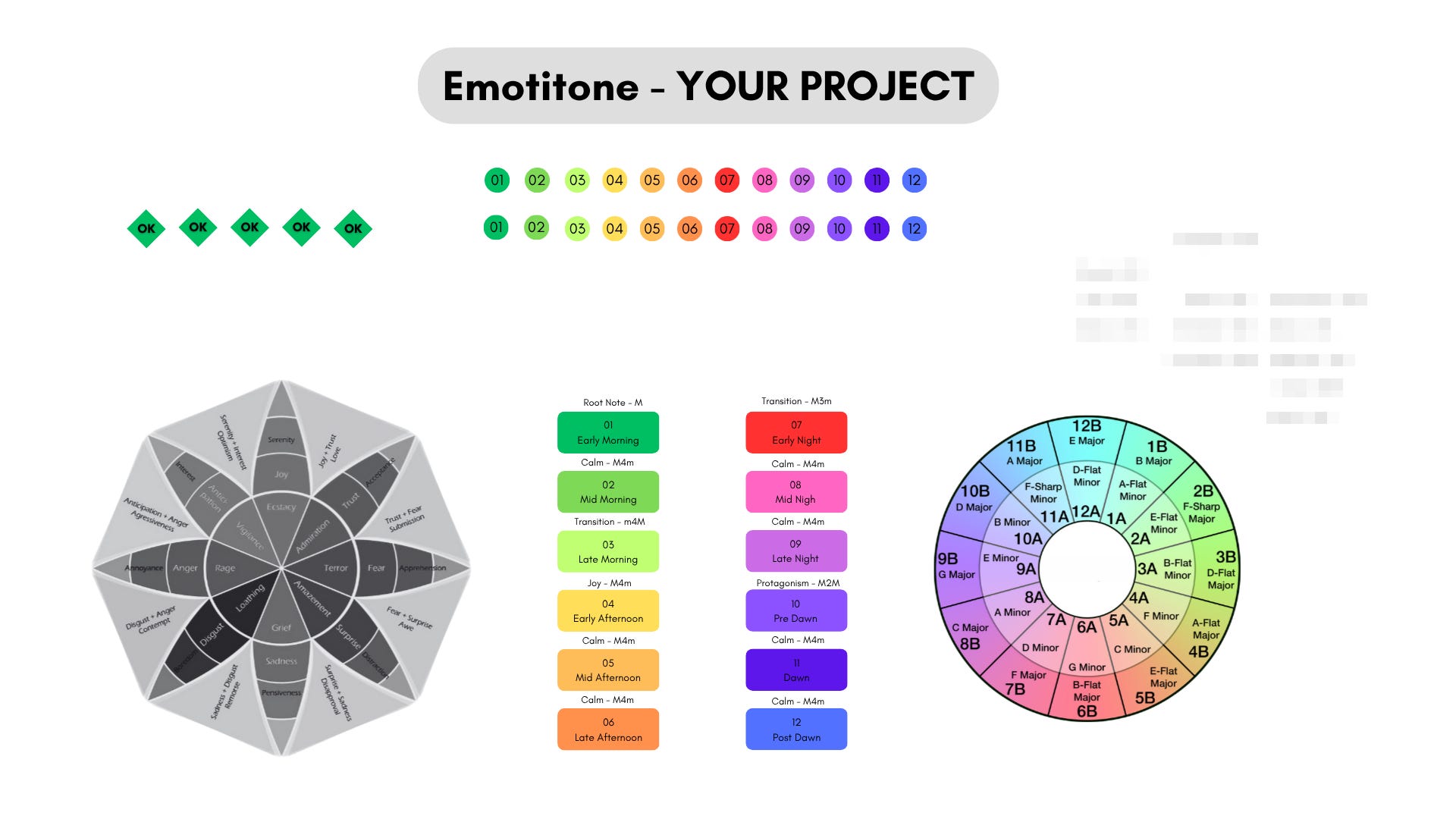
EmotiTone is an emotion-to-audio specification system.
It turns emotion into constraints you can test.
But there’s a second mechanism that matters just as much as the spec itself: working in consonance with the director, the designers, and the developers.
If the director can’t tell you what the audience should feel moment by moment, your “emotion” target is vague.
If you don’t understand what the designers are visually building (scale, pacing, lighting, attention cues) your sound will fight the image.
If you don’t understand what the developers can actually implement (budget, triggers, states, performance constraints) your “idea” stays a demo, not a system.
👉 So the spec isn’t something I write in isolation. It’s a shared contract across disciplines:
What the director intends, what the visual language communicates, and what the engine can reliably execute.
Below are the six constraints I write before designing.
State sequence. What the body should move through over time. Example: shock → orientation → empathy → resolve. This is where I align tightly with direction: what is the intended emotional beat here, and what is the next beat supposed to feel like?
Orientation rules. What must be physically legible. Distance cues. Direction of arrival. Inside versus outside anchors. Scale consistency. This is where design matters: if the scene uses a visual anchor to orient attention, sound should reinforce it and not introduce competing anchors.
Density budget. How much simultaneous information the nervous system can hold before it starts to float. This decides layering, motion, and how “busy” the soundfield is allowed to be. And it has a direct engineering consequence: CPU/voice counts, streaming limits, and how many systems can talk at once.
Silence budget. Where integration time is mandatory. Silence is structural. It is how the body catches up. In implementation terms, this often means explicitly designing “integration windows” (not just turning things down), so interaction and narrative beats have room to land.
Harmonic behavior. Rules of tension and resolution over time. Not “sad versus happy.” More like: how often do we allow resolution, and what does it cost? This is where the craft stops being a static mix. It becomes a behavior that can survive branching, pacing changes, and player choice.
Ethical boundaries. (and this is MOST important) What we refuse to do for attention. No cheap intensity. No manipulation that breaks dignity. No sonic lies the story cannot pay off. This is direction and production policy as much as it is aesthetics. If the project’s ethics aren’t explicit, the pressure of deadlines will make the decision for you.
After that, the work is execution: design, composition, implementation, and protection inside the engine.
👆That last step is where many projects lose the arc. 👆
A mix can sound beautiful in a digital audio workstation (DAW), then ship something else in headset.
To prevent that drift, I treat implementation as part of authorship:
I translate the spec into states, transitions, parameters, and mix rules.
I pressure-test it against real runtime constraints.
I iterate with direction and design when interaction changes the pacing.
✅ Nice audio is easy to describe. Reliable emotion design is harder. That is why it is valuable.
Proof point: I pressure-tested this approach on three projects I delivered this month. And all these “rules” translated beautifully into the final deliveries, as per user testing and feedback from them.
If you’re producing interactive work, the question is not “does it sound good?” The question is: what emotional state are we reliably putting people in, and how do we know?
Best wishes,
Billy.
If you came this far, you know that sound is not finish. It is architecture.
I design spatial audio systems for VR, XR, and immersive media, building the sonic environments that shape where audiences look, what they feel, and how long they stay present.
I’m Billy Mello. 30+ years across broadcast, interactive, and immersive media. Emmy-nominated. Peabody Award-winning.
Three ways to work with me
Audit: identify what will break later
Sprint: prototype one scene + lock constraints early
Full delivery: direction + implementation support
Transparent trade-off: any of these needs at least one playtest loop. No loop, we are guessing.
Best wishes,
Billy.